Solving Machine Learning Performance Anti-Patterns: a Systematic Approach
June 24, 2021
Intro #
This article is a high-level introduction to an efficient worfklow for optimizing runtime performance of machine learning systems running on the GPU. This approach is not revolutionary — we simply find the biggest problems and then fix them, again and again — but without the right tools and knowledge it’s hard to be disciplined and efficient in this cycle.
Without knowing exactly why a system is slow there is a temptation to use the “it could be this” approach — successively guessing at interventions which might fix the problem. Guessing is usually a waste of time when it comes to any optimization work. NVIDIA’s Nsight Systems helps us quickly understand system performance, and it’s one of the main tools I use when tuning ML systems for production.
Once we have identified the main performance problems, being able to solve these is a matter of understanding the system (software and hardware) deeply enough and using the right tool for the job. This article will explain the techniques and tools I use — when to apply them and why they work.
I’ll introduce a set of common utilization patterns and outline effective approaches to improve performance. We’ll dig into these patterns later on:

In my consulting work I’ve seen many startups trying to take research models into production and facing major performance or cost hurdles. Using this systematic approach I’ve achieved throughput improvements of up to 15X with just a few days of intense work. A systematic approach delivers the biggest improvements first, and is the most efficient path to delivering well-tuned systems.
Finding the Patterns #
Tracing with Nsight Systems #
NVIDIA’s Nsight Systems is easy to get started with and delivers a rich trace of key resources and events. If you learn one tool for understanding the performance of machine learning systems, this should be it.
We can begin tracing without any changes to application code — as simple as this:
$ nsys profile -t cuda,cudnn,nvtx,osrt -o <report_path> <process_command_line>
This will produce a report at <report_path> which can be loaded and analyzed using the Nsight Systems desktop client. Here’s an example:
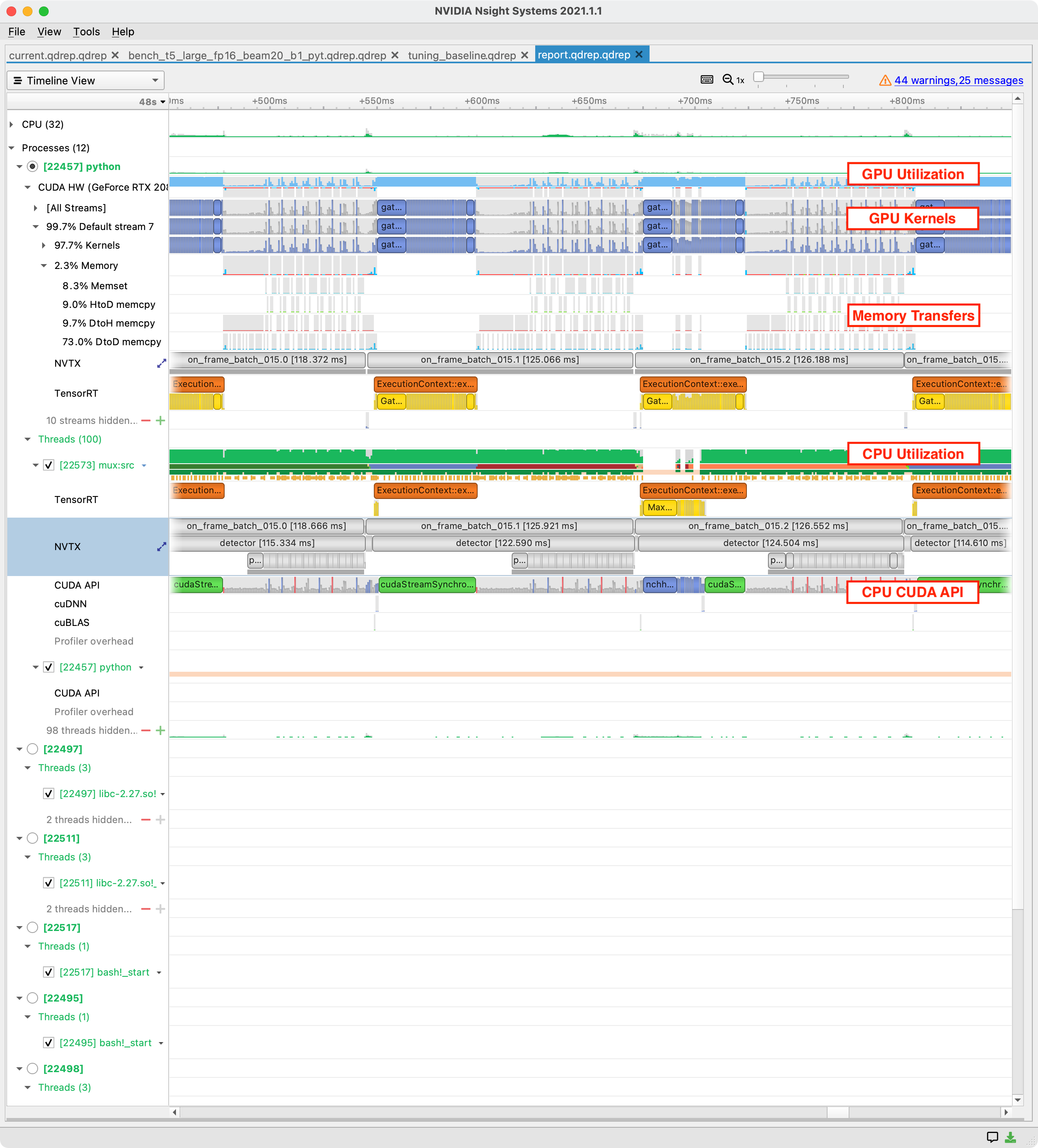
Looking at this sample Nsight Systems report, we can see several important features:
- Traces of aggregated resource consumption over time (GPU and CPU utilization) tell us generally where to focus.
- Ranges in several tracks corresponding to on-device kernel executions, memory transfers, synchronization activity, and host CUDA API calls.
- Activity is split into traces for any GPUs, and also for the host where it is subdivided by threads.
NVTX: Mapping Logic to Metrics #
NVTX is an indispensible toolkit that hugely increases the power of Nsight Systems reports for optimization. Using NVTX we can easily delineate logical sections of model code and these appear as highly precise ranges in Nsight Systems traces. Viewing resource consumption metrics and low-level operations (CUDA kernels, memory transfers, synchronization points) alongside your logical ranges allows us to deeply understand execution performance.
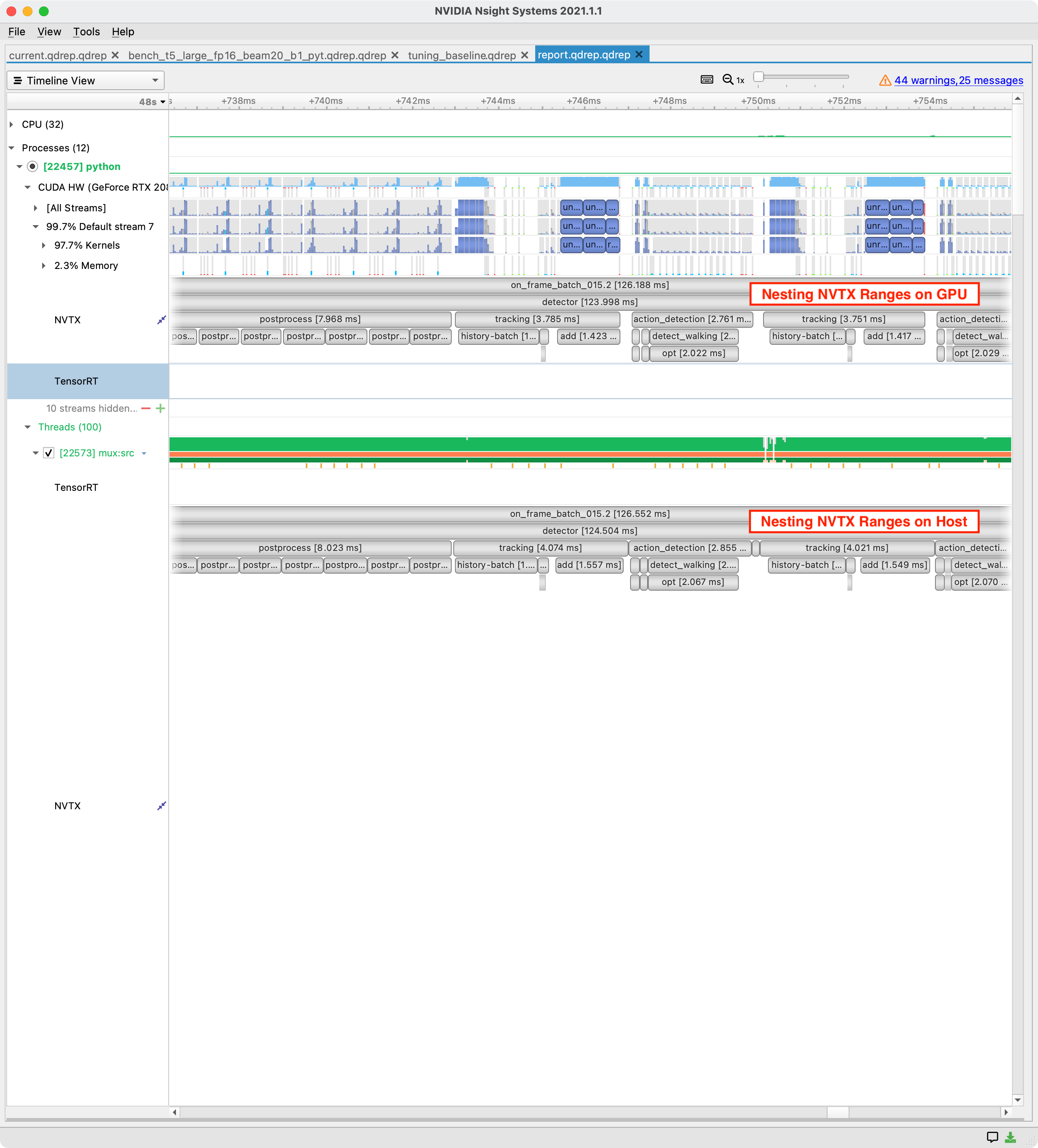
NVTX Ranges on Host and Device May Not Match, but Both Are Correct
The host submits work via a command queue to the GPU for execution. Due to this asynchronous relationship the start of an NVTX range in the host process will often be well before the start of that range on the GPU.
NVTX can be accessed as a C or Python API. I use the following context manager which hooks into the Pytorch NVTX bindings:
@contextlib.contextmanager
def nvtx_range(msg):
depth = torch.cuda.nvtx.range_push(msg)
try:
yield depth
finally:
torch.cuda.nvtx.range_pop()
Here’s an example of usage:
class Net(torch.nn.Module):
def forward(self, X):
with nvtx_range('Net.forward'):
with nvtx_range('normalize'):
X = X.half().divide(255)
with nvtx_range('blur'):
return gaussian_blur(X, kernel_size=5, sigma=3)
Understanding the Patterns #
In order to translate the information in an Nsight Systems report into actual insight, an understanding of how the host (CPU) and device (GPU/TPU) work together is essential.
Host/Device System Concept #
All models are wrong, but some are useful — we need a simple abstraction of the host/device relationship so we can reason about performance and understand the patterns we see in Nsight traces.
The devices (GPUs) in a system behave like very powerful asynchronous coprocessors. The host (CPU) submits fully-specified chunks of work into a queue and the device performs these operations asynchronously and independently, only returning results to the host when requested via a memory transfer.
At this level of abstraction, an example trace might look like this:

Given this asynchronous relationship, the significant latency in host/device communication, and the fact that the device is far more powerful than the host in raw compute terms, some guidelines become clear:
- Do as much work on the device as possible.
- Work hard to remove synchronization points between host and device, as these can leave either side idle.
- If possible, reduce communication (API calls and memory transfers) between host and device by batching or combining operations.
These principles are in rough order of priority, and like all guidelines there are times they should be broken.
Next we’ll take a tour through some major patterns of suboptimal performance — many of which map directly to violations of these principles.
ML Optimization Pattern Language #
A catalog of common patterns and sample solutions — I can call that a pattern language, right? If not, here’s a link to a Hacker News thread where you can call me pretentious.
Machine learning systems show distinct patterns of resource consumption, and each of these patterns requires a different approach to improving performance.
Real-world systems usually exhibit several different patterns in different parts of the inference pipeline so quite often we’ll need to apply multiple of the approaches below. For example, post-processing logic is highly prone to being CPU compute bound or synchronization bound, whereas the backbone of vision models are often GPU compute bound.
Below I’ll show the most common trace patterns in my experience tuning inference pipelines and detail some approaches to optimization in each case.
Pattern: GPU Compute Bound #
In this pattern, the GPU is continually running CUDA kernels corresponding to tensor transformations, activation functions, weight multiplications etc. These operations are being enqueued by the host faster than the GPU can execute them, so the GPU is able to stay at high utilization. In this state, a less fine-grained tool like nvidia-smi would show >90% GPU utilization.

Nsight Systems Example #
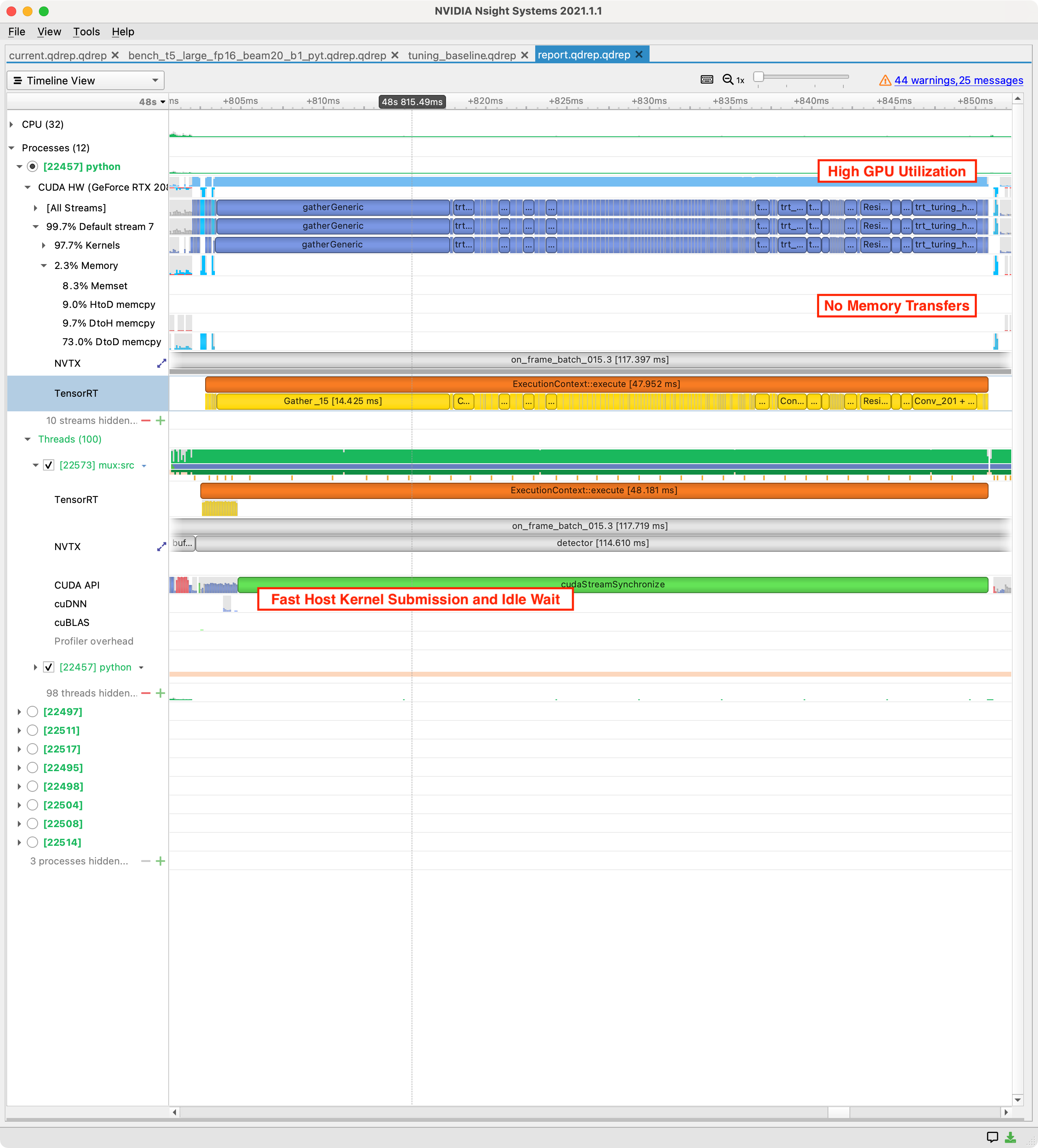
Distinguishing Features #
- GPU utilization resource trace shows >90%, without gaps, and kernels are executed sequentially without delays.
- GPU memory transfers are absent or rare, especially DtoH or HtoD transfers.
- Host CUDA API trace shows kernels being submitted faster than the GPU completes them, and includes waiting time for synchronization.
Improving GPU Compute Performance #
In the scope of machine learning systems, this pattern is a good one to see. It means you are using your most expensive hardware with high utilization and you are avoiding the very common pitfall of mixing CPU and GPU computation together. However, if a large portion of your run time is GPU compute bound then this represents a good opportunity for optimization.
Optimization approaches #
- Use a lower-precision version of your model: float16 or even int8 quantization can give up to 2x or 4x improvements in throughput.
- Use a profiling-based model compiler like TensorRT: this will fuse layers, use optimized kernels, and determine optimal kernel launch parameters for your specific hardware.
- Perform model-pruning using a framework like the Transfer Learning Toolkit (TLT): reduce the number of computations performed with a small impact to accuracy.
- Use more powerful GPUs: spending more money is usually not the goal, however this is the only trace pattern where upgrading GPUs is a good choice.
Pattern: CPU CUDA API Bound #
In terms of raw compute GPUs are surprisingly powerful and it is easy to get into a situation where your host/CPU is submitting work to the GPU as fast as possible but still cannot keep up. The CPU is constantly sending work into a non-blocking command queue, but the GPU finishes the work in less time than it takes to configure and enqueue. Unsurprisingly, this is much more likely to be a problem with a Python host process.

Nsight Systems Example #
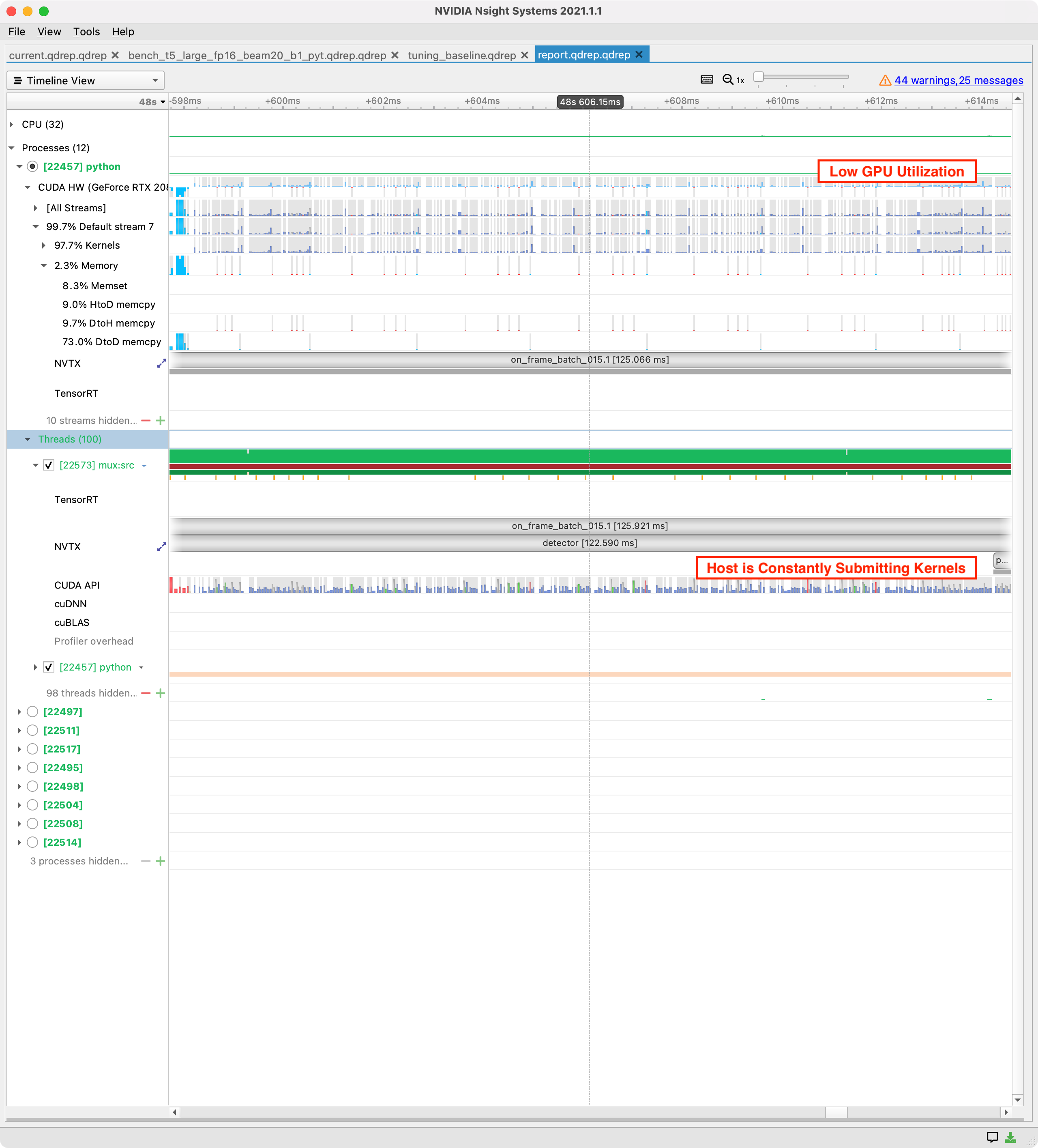
Distinguishing features #
- CPU utilization is >90% and the host is continuously making CUDA API calls.
- GPU utilization is <80%, and contains frequent gaps.
- Memory transfers between host and device do not dominate the trace.
Improving CUDA API Performance #
Improving performance when you are spending all your host time on submitting tensor operations can be very easy or very challenging, depending on whether your existing logic incorporates a batch dimension. If all processing is expressed in terms of a batch then increasing this batch dimension is a great way to shift the bottleneck from CPU to GPU.
If your current logic is expressed per item (frame by frame, for example) then you’ll probably need to think through every line of the code as you implement batching. On the positive side, the results of this kind of transformation can be very impressive and with the GPU now a bottleneck many further optimizations have been unlocked.
Optimization approaches #
- Increase batch sizes, sending more work to the GPU per API call.
- Export and run this logic with TorchScript, resulting in much faster submission of operations.
- Rewrite tensor operations to do more work with fewer API calls.
- Reimplement your logic in C/C++.
Pattern: Synchronization Bound #
This pattern commonly occurs in conjunction with CUDA API bound code, often during post-processing where small GPU operations are mixed with dependent CPU operations. This alternating GPU/CPU computation usually requires many small memory transfers and associated syncronization points, and you pay a latency cost each time. If you are writing post-processing logic on the GPU but find yourself writing loops in host code, then you may be creating this pattern.

Nsight Systems Example #
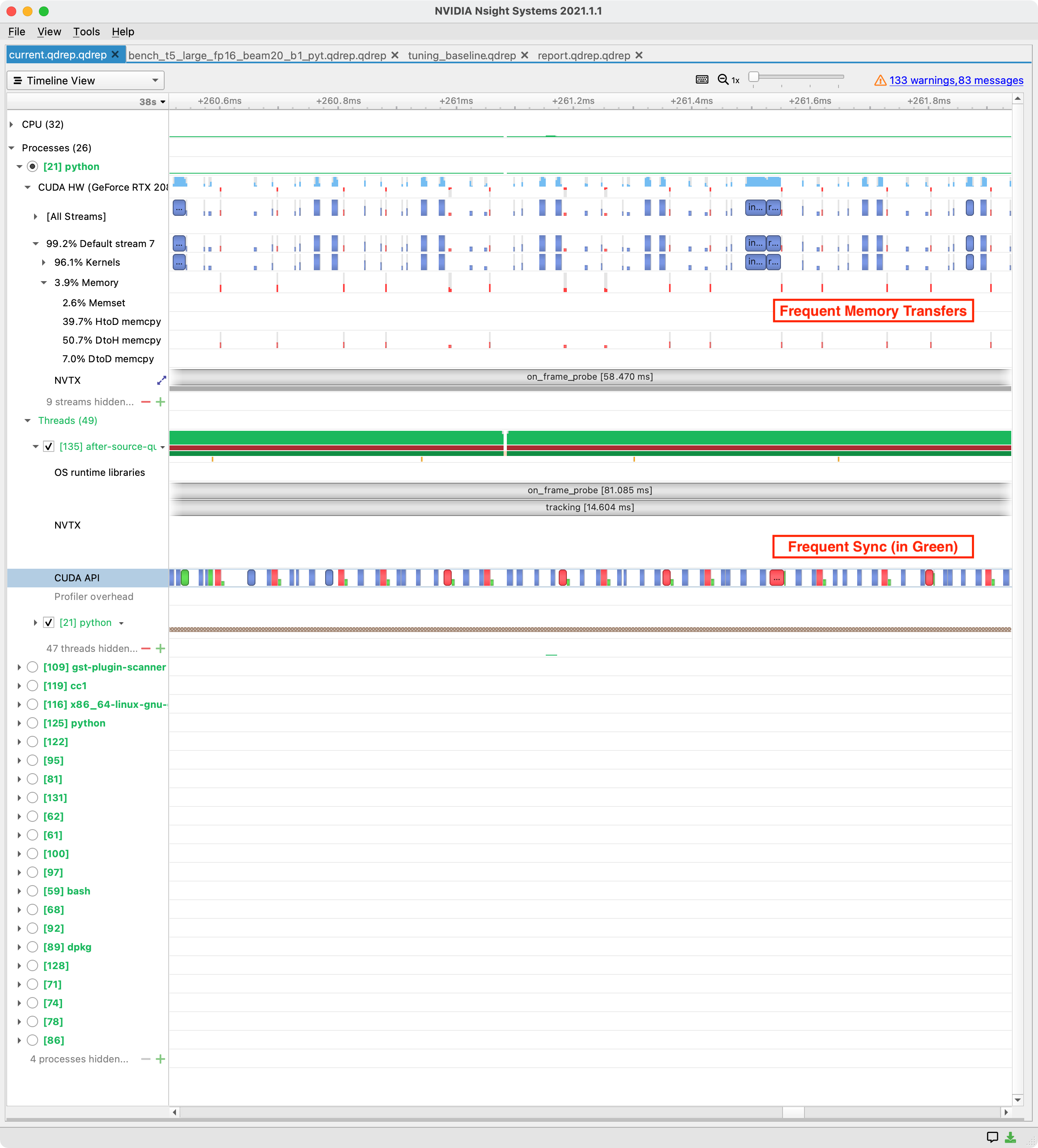
In this heavily zoomed-in trace, note all the green synchronization points in the CUDA API trace, and all the corresponding tiny DtoH (device to host) memory transfers. This is a classic issue with post-processing logic.
Distinguishing features #
- CPU utilization is moderate.
- GPU utilization is moderate.
- Synchronization points dominate the trace, usually associated with small memory transfers.
Reducing Synchronization #
Synchronization is required when a result from either host or device is needed on the other, so the key to solving this pattern is to fix interleaved host/device computation.
Sometimes this can be done by turning loops into vectorized tensor ops on the GPU, sometimes splitting out the algorithm into batched GPU computation and subsequent looping host computation can help, and sometimes moving everything to the host comes out ahead. A low-effort fix is to increase batch sizes which proportionally reduces interleaved computation, but doesn’t fix the underlying problem.
Optimization approaches #
- Convert as many operations as possible to execute on the GPU.
- Deinterleave GPU/CPU processing, computing large batches on GPU then consuming these as required in the host process.
- Alternatively, in rare cases converting all operations to execute on CPU may increase performance.
- Increase batch sizes, allowing more work to happen on the GPU between synchronization points.
Pattern: CPU Compute Bound #
If your machine learning process is CPU compute bound then you may have a simple bug where some portion of your model code is running on CPU rather than GPU.
Legacy machine learning systems used to do preprocessing and postprocessing using CPU only — only using the GPU for the core model. We now have hardware accelerated augmentation libraries and flexible on-GPU transformation pipelines, so for either training or production inference doing substantial preprocessing or postprocessing on CPU rarely makes sense.
If you have this pattern and it was an honest mistake, I forgive you.

Nsight Systems Example #
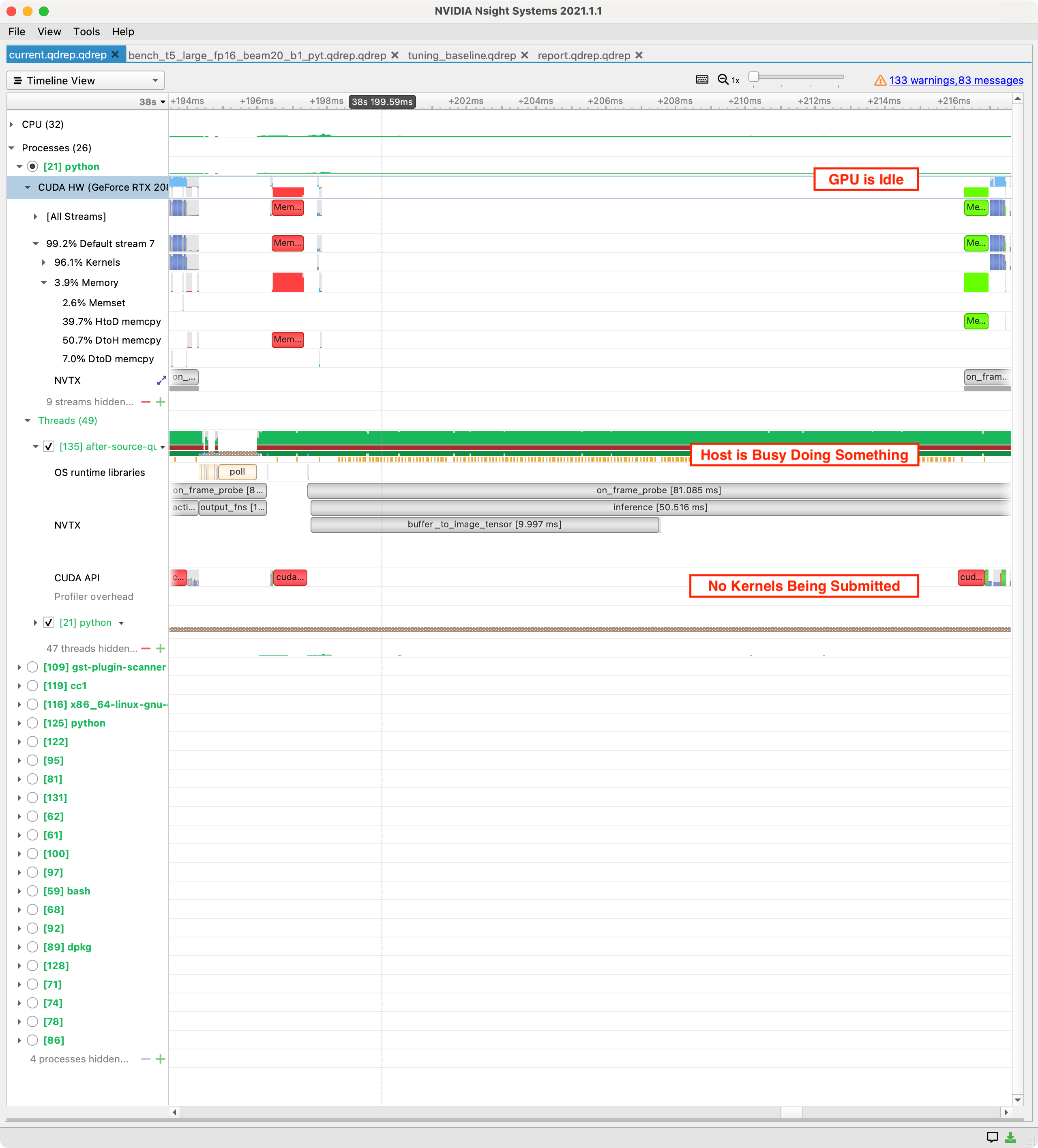
The Nsight Systems trace above looks horrific.
Distinguishing features #
- CPU utilization is >90% and few CUDA API calls are being made.
- GPU is mostly idle, with no or few memory transfers.
Optimization approaches #
- Move the compute to GPU by expressing the algorithm as highly vectorized tensor operations.
- If work cannot be moved to the GPU, do this work asynchronously with respect to tasks which can use the GPU.
Conclusion #
The most important idea in this post is that of being systematic when optimizing performance — measuring and observing well-defined problems before you spend time fixing them. This idea is well known but not well followed (you are fine, I am talking about other people).
With a familiar tracing tool close to hand, it becomes easy and natural to focus on the biggest opportunities and avoid wasting time on problems that don’t exist. Nsight Systems is in a sweet spot of being easy to use, highly detailed and accurate, and straightforward to analyze once you know what you’re looking for.
The utilization patterns described above, together with the suggested optimization approaches, are the highest-level distillation possible of my experience tuning production machine learning systems. I hope you find them useful!
Join Me at WOMBO.ai 🌈 #
If you liked this article you’re probably the kind of person we’re looking to work with at WOMBO.ai.
WOMBO.ai is Canada’s fastest growing app (ever), a true rocketship with over 50M installs in the last three months and closing in on a billion lipsync videos created. We’re looking for early employees and leaders across a bunch of different roles: check the careers page!
The team has an expansive vision of what is possible with cutting edge ML and synthetic media, and the funding to make this happen. If you want to work on SoTA generative ML or push the boundaries of production inference efficiency, then come work with me at WOMBO. :)