Object Detection at 1840 FPS with TorchScript, TensorRT and DeepStream
October 17, 2020
Intro #
Previously, we took a simple video pipeline and made it as fast as we could without sacrificing the flexibility of the Python runtime. It’s amazing how far you can go — 9 FPS to 650 FPS — but we did not reach full hardware utilization and the pipeline did not scale linearly beyond a single GPU. There is evidence (measured using gil_load) that we were throttled by a fundamental Python limitation with multiple threads fighting over the Global Interpreter Lock (GIL).
In this article we’ll take performance of the same SSD300 model even further, leaving Python behind and moving towards true production deployment technologies:
-
TorchScript. Instead of running directly in the Pytorch runtime, we’ll export our model using TorchScript tracing into a form that can be executed portably using the
libtorchC++ runtime. -
TensorRT. This toolset from Nvidia includes a “deep learning inference optimizer” — a compiler for optimizing CUDA-based computational graphs. We’ll use this to squeeze out every drop of inference efficiency.
-
DeepStream. While Gstreamer gives us an extensive library of elements to build media pipelines with, DeepStream expands this library with a set of GPU-accelerated elements specialized for machine learning.
These technologies fit together like this:

This article will not be a step-by-step tutorial with code examples, but will show what is possible when these technologies are combined. The associated repository is here: github.com/pbridger/deepstream-video-pipeline.
🔥TorchScript vs TensorRT🔥 #
Both TorchScript and TensorRT can produce a deployment-ready form of our model, so why do we need both? These great tools may eventually be competitors but in 2020 they are complementary — they each have weaknesses that are compensated for by the other.
TorchScript. With a few lines of torch.jit code we can generate a deployment-ready asset from essentially any Pytorch model that will run anywhere libtorch runs. It’s not inherently faster (it is submitting approximately the same sequence of kernels) but the libtorch runtime will perform better under high concurrency. However, without care TorchScript output may have performance and portability surprises (I’ll cover some of these in a later article).
TensorRT. An unparalleled model compiler for Nvidia hardware, but for Pytorch or ONNX-based models it has incomplete support and suffers from poor portability. There is a plugin system to add arbitrary layers and postprocessing, but this low-level work is out of reach for groups without specialized deployment teams. TensorRT also doesn’t support cross-compilation so models must be optimized directly on the target hardware — not great for embedded platforms or highly diverse compute ecosystems.
Let’s begin with a baseline from the previous post in this series — Object Detection from 9 FPS to 650 FPS in 6 Steps.
Stage 0: Python Baseline #
| Code | Nsight Systems Trace | Gstreamer Pipeline |
|---|---|---|
| tuning_postprocess_2.py | tuning_postprocess_2.qdrep | tuning_postprocess_2.pipeline.dot.png |
{kind=link}
The Postprocessing on GPU stage from my previous post is logically closest to our first DeepStream pipeline. This was a fairly slow, early stage in the Python-based optimization journey but limitations in DeepStream around batching and memory transfer make this the best comparison.
This Python-based pipeline runs at around 80 FPS:
After we get a basic DeepStream pipeline up and running we’ll empirically understand and then remove the limitations we see.
Stage 1: Normal DeepStream — 100% TorchScript #
| Code | Nsight Systems Trace | Gstreamer Pipeline |
|---|---|---|
| ds_trt_1.py, ds_tsc_1.py, ds_ssd300_1.py | ds_1_1gpu_batch16_host.qdrep | ds_1_1gpu_batch16_host.pipeline.dot.png |
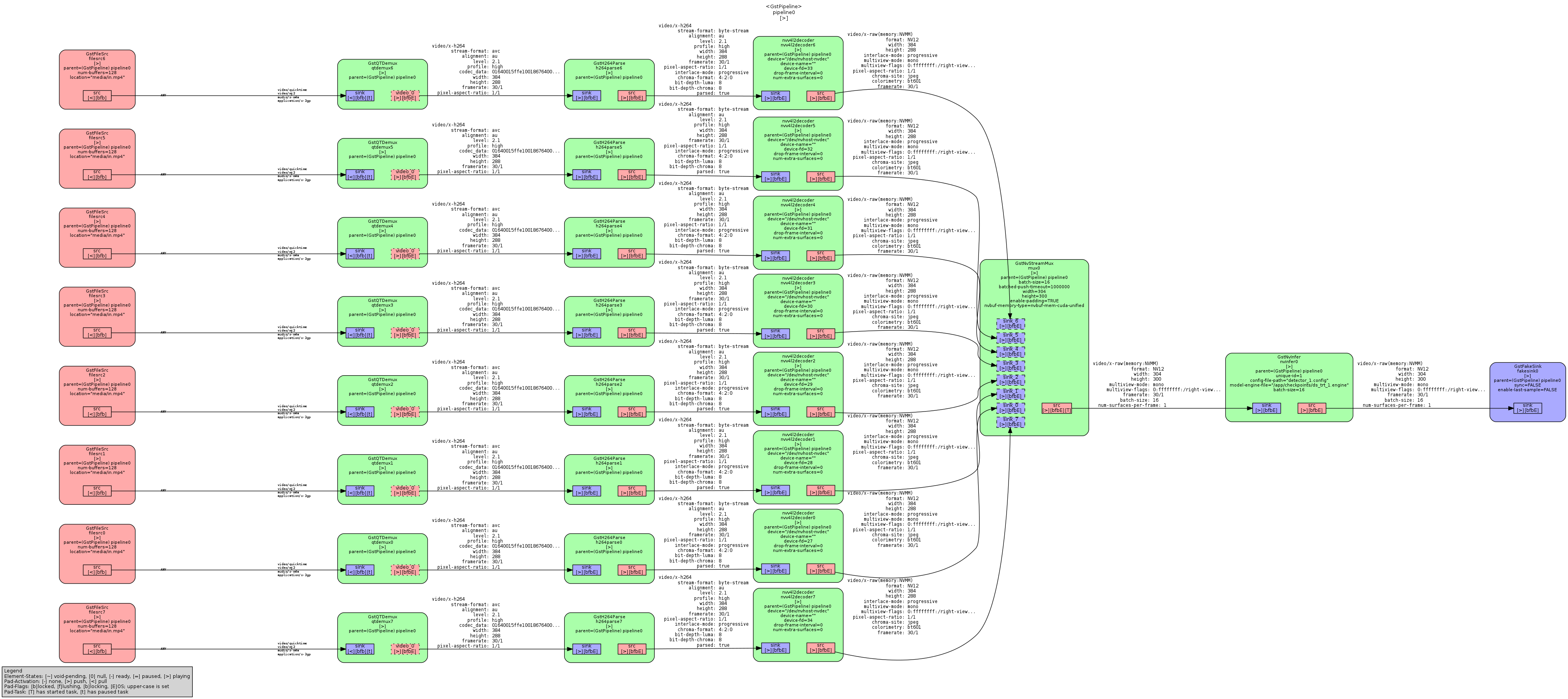{kind=link}
Our approach to using TorchScript and TensorRT together in a DeepStream pipeline will be to construct a hybrid model with two sequential components — a TensorRT frontend passing results to a TorchScript backend which completes the calculation.
Hybrid DeepStream Pipeline #
Our hybrid pipeline will eventually use the nvinfer element of DeepStream to serve a TensorRT-compiled form of the SSD300 model directly in the media pipeline. Since TensorRT cannot compile the entire model (due to unsupported ONNX ops) we’ll run the remaining operations as a TorchScript module (via the parse-bbox-func-name hook).
However, the first pipeline will be the simplest possible while still following the hybrid pattern. The TensorRT model does no processing and simply passes frames to the TorchScript model, which does all preprocessing, inference, and postprocessing. 0% TensorRT, 100% TorchScript.
This pipeline runs at 110 FPS without tracing overhead. However, this TorchScript model has already been converted to fp16 precision so a direct comparison to the Python-based pipeline is a bit misleading.
Let’s drill into the trace with Nvidia’s Nsight Systems to understand the patterns of execution. I have zoomed in to the processing for two 16-frame batches:

Looking at the red NVTX ranges on the GstNvInfer line we can see overlapping ranges where batches of 16 frames are being processed. However, the pattern of processing on the GPU is quite clear from the 16 utilisation spikes — it is processing frame-by-frame. We also see constant memory transfers between device and host.
Drilling in to see just two frames of processing, the pattern is even more clear:
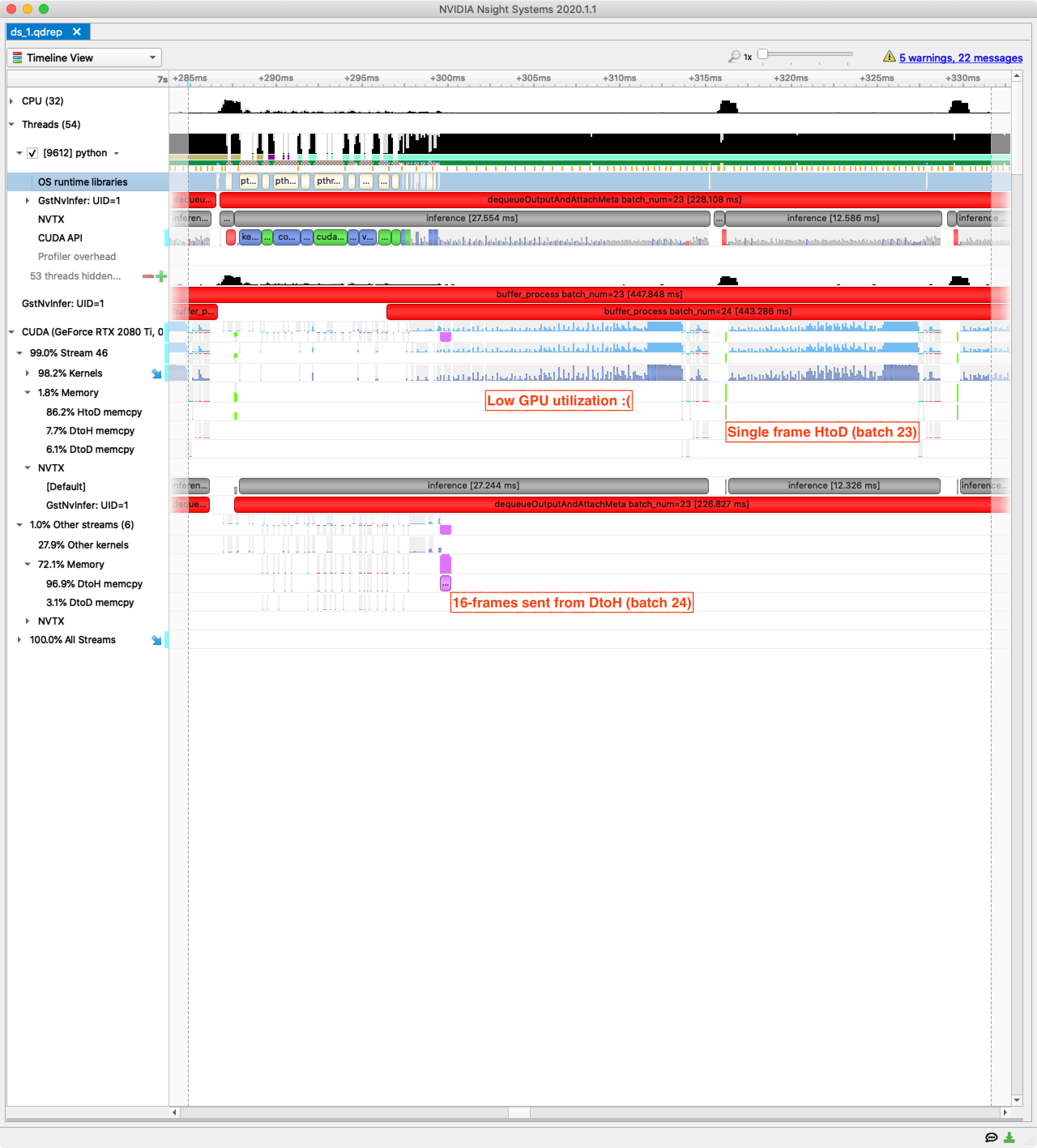
With a little knowledge of how DeepStream works the problem is clear:
nvinfersends batches of frames to the configured model engine (our empty TensorRT component) — great.nvinferthen sends the model output frame by frame to the postprocessing hook (our TorchScript component).
Since we have put our entire model into a TorchScript postprocessing hook we are now processing frame by frame with no batching, and this is causing very low GPU utilisation. (This is why we are comparing against a Python pipeline with no batching).
We are using DeepStream contrary to the design, but to build a truly hybrid TensorRT and TorchScript pipeline we need batched postprocessing.
DeepStream Limitation: Postprocessing Hooks are Frame-by-Frame
The design of
nvinferassumes model output will be postprocessed frame-by-frame. This makes writing postprocessing code a tiny bit easier but is inefficient by default. Preprocessing, inference and postprocessing logic should always assume a batch dimension is present.
The Nsight Systems view above also shows a pointless sequence of device-to-host then host-to-device transfers. The purple device-to-host memory transfer is due to nvinfer sending tensors to system memory, ready for the postprocessing code to use it. The green host-to-device transfers are me putting this memory back on the GPU where it belongs.
DeepStream Limitation: Postprocessing is Assumed to Happen on Host
This is a legacy of early machine learning approaches. Modern deep learning pipelines keep data on the GPU end-to-end, including data augmentation and postprocessing. See Nvidia’s DALI library for an example of this.
Okay, time to hack DeepStream and remove these limitations.
Stage 2: Hacked DeepStream — 100% TorchScript #
| Code | Nsight Systems Trace | Gstreamer Pipeline |
|---|---|---|
| ds_trt_2.py, ds_tsc_2.py, ds_ssd300_2.py | ds_2_1gpu_batch16_device.qdrep | ds_2_1gpu_batch16_device.pipeline.dot.png |
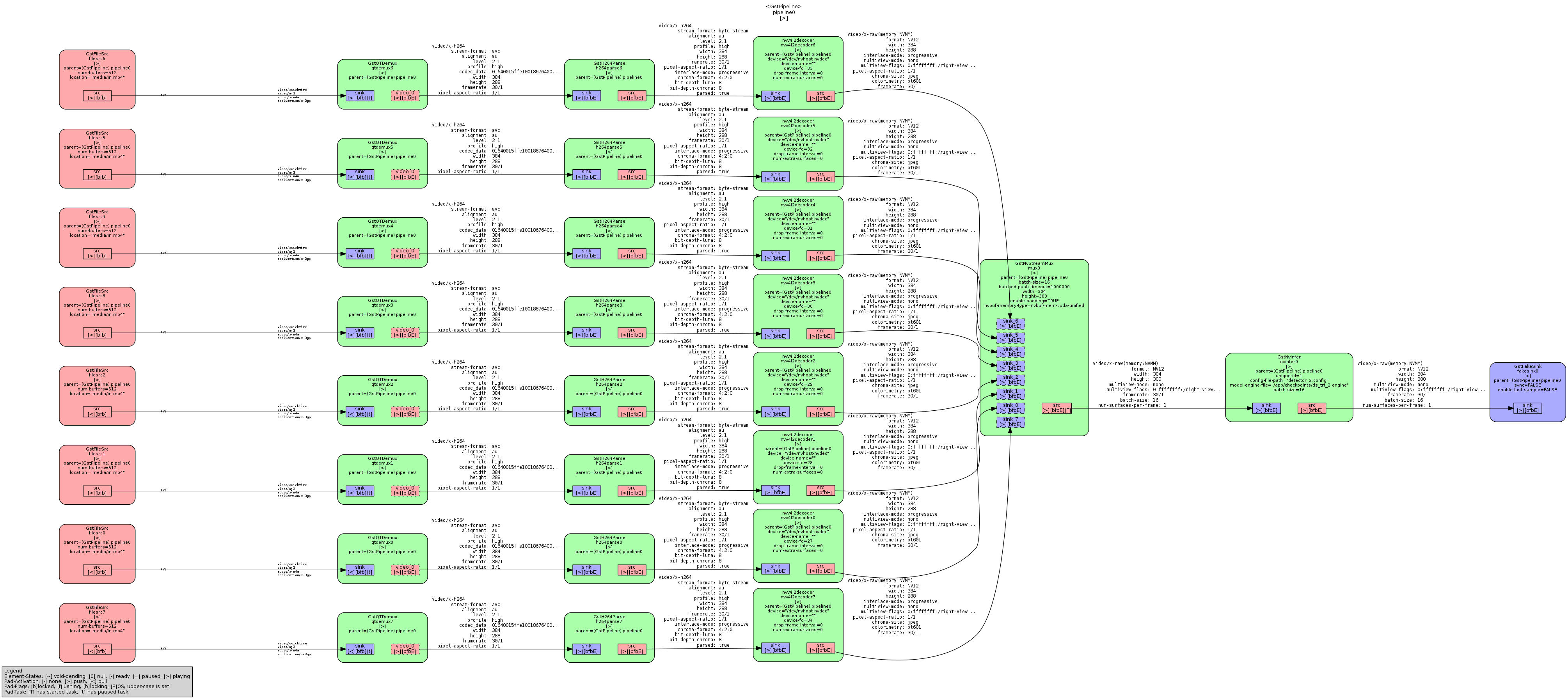{kind=link}
Thankfully, Nvidia have provided source for the nvinfer pipeline element. I’ve made two changes to better support our approach of doing significant work in the postprocessing hook and fix the above limitations:
nvinfermodel engine output is now sent in a single batch to the postprocessing hook.- Model output tensors are no-longer copied to host, but are left on the device.
Thesenvinferchanges are unreleased and are not present in the companion repository (github.com/pbridger/deepstream-video-pipeline) because they are clearly derivative ofnvinferand I’m unsure of the licensing. Nvidia people, feel free to get in touch: paul@paulbridger.com.
With hacked DeepStream and no model changes at all this pipeline now hits 350 FPS when measured with no tracing overhead. This is up from 110 FPS with regular DeepStream. I think we deserve a chart:
The Concurrency 1x2080Ti stage from the Python pipeline is now the closest comparison both in terms of FPS and optimizations applied. Both pipelines have batched inference, video frames decoded and processed on GPU end-to-end, and concurrency at the batch level (note the overlapping NVTX ranges below). One additional level of concurrency in the Python pipeline is multiple overlapping CUDA streams.
The Nsight Systems view shows processing for several 16-frame batches:
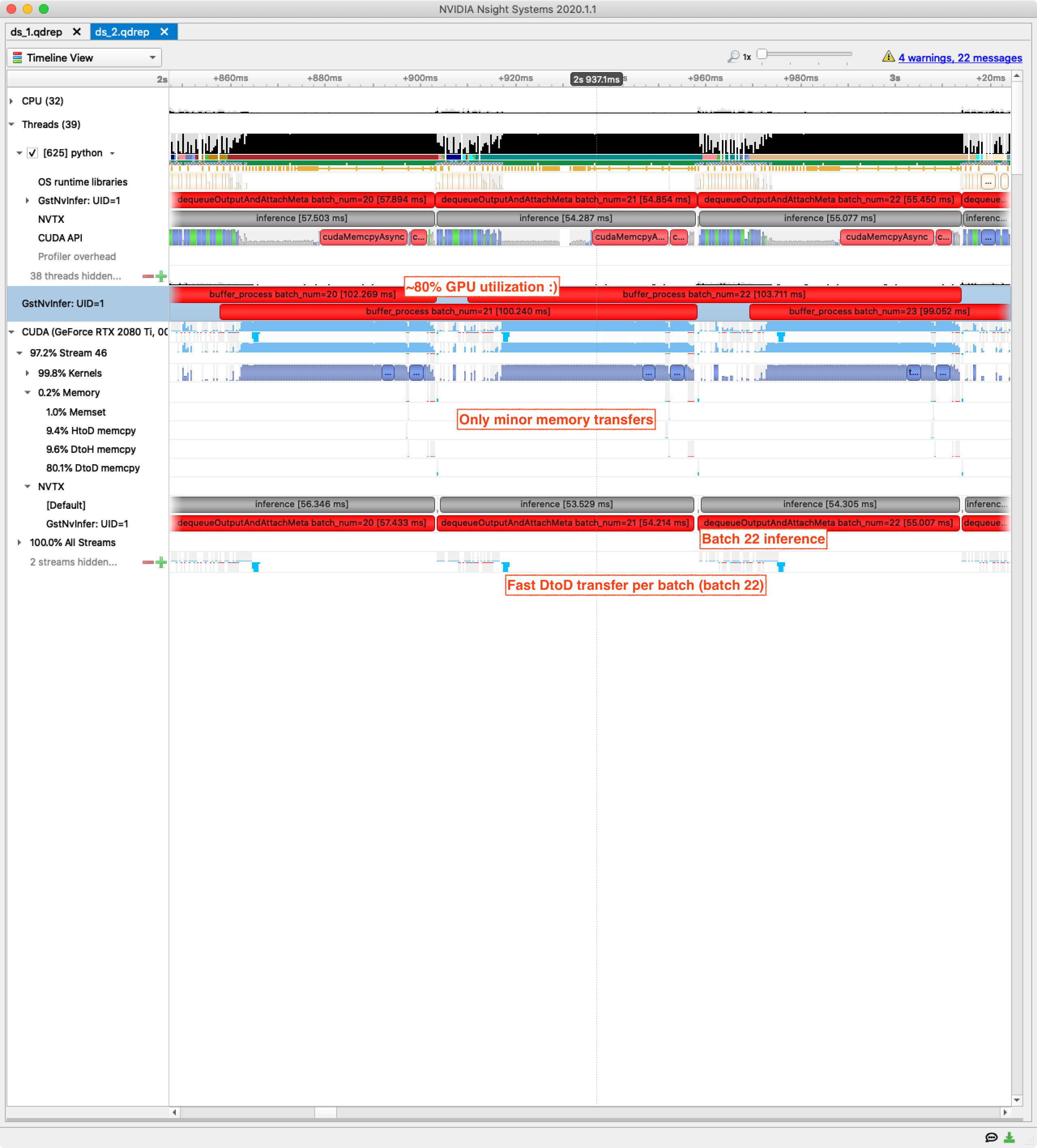
We now have good GPU utilization and very few needless memory transfers, so the path forward is to optimize the TorchScript model. Until now the TensorRT component has been entirely pass-through and everything from preprocessing, inference and postprocessing has been in TorchScript.
It’s time to start using the TensorRT optimizer, so get ready for some excitement.
Stage 3: Hacked DeepStream — 80% TensorRT, 20% TorchScript #
| Code | Nsight Systems Trace | Gstreamer Pipeline |
|---|---|---|
| ds_trt_3.py, ds_tsc_3.py, ds_ssd300_3.py | ds_3_1gpu_batch16_device.qdrep | ds_3_1gpu_batch16_device.pipeline.dot.png |
{kind=link}
According to Nvidia, TensorRT “dramatically accelerates deep learning inference performance” so why not compile 100% of our model with TensorRT?
The Pytorch export to TensorRT consists of a couple of steps, and both provide an opportunity for incomplete support:
- Export the Pytorch model to the ONNX interchange representation via tracing or scripting.
- Compile the ONNX representation into a TensorRT engine, the optimized form of the model.
If you try to create an optimized TensorRT engine for this entire model (SSD300 including postprocessing), the first problem you will run into is the export to ONNX of the repeat_interleave operation during postprocessing. Pytorch 1.6 does not support this export, I don’t know why.
Just like writing C++ in the days before conforming compilers, it’s often possible to rewrite model code to work around unsupported operations. See ds_ssd300_5.py for an example that replaces repeat_interleave and will now export to ONNX. However, now the TensorRT compilation fails with another unsupported operation — No importer registered for op: ScatterND.
Dealing with all this is fine if you have a dedicated deployment team — simply write custom plugins and CUDA kernels — but most teams don’t have those resources or time to invest in this.
This is why the hybrid approach works so well — we can get the benefits of TensorRT optimization for most of our model and cover the rest with TorchScript.
Speaking of benefits:
920 FPS up from 350 FPS is a huge jump, and we are still only using a single 2080Ti GPU. Let’s check Nsight Systems to understand how this can be possible:
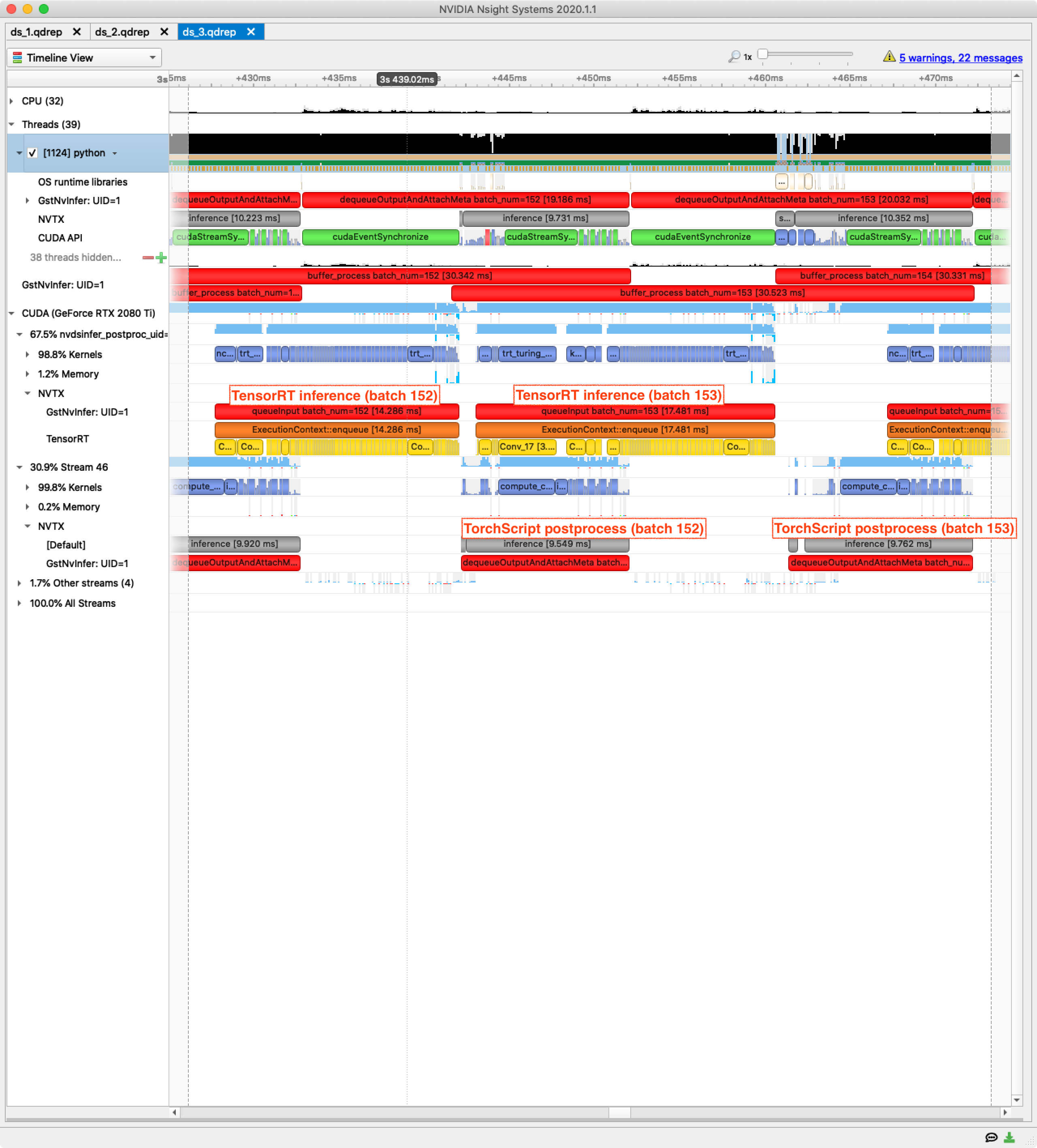
Two important things to note:
- TensorRT inference for batch N is now interleaved/concurrent with TorchScript postprocessing for batch N-1, helping to fill in utilization gaps.
- The TensorRT preprocessing and inference are massively faster than the TorchScript version. Around 43ms of TorchScript preprocessing and inference have turned into around 16ms of equivalent TensorRT processing.
This Nsight Systems trace output now looks a little like what we were aiming for:
Given the awesome improvement TensorRT gave us, did we really need to hack DeepStream?
Stage 4: Normal DeepStream — 80% TensorRT, 20% TorchScript #
| Code | Nsight Systems Trace | Gstreamer Pipeline |
|---|---|---|
| ds_trt_4.py, ds_tsc_4.py, ds_ssd300_4.py | ds_4_1gpu_batch16_host.qdrep | ds_4_1gpu_batch16_host.pipeline.dot.png |
{kind=link}
In short, yes, we did need to hack DeepStream to get the best throughput. Unless you like the sound of 360 FPS when you could be hitting 920 FPS. This is a step backwards so I’m not adding it to our chart.
Here is the trace when we run the TensorRT-optimized model with the TorchScript final processing:
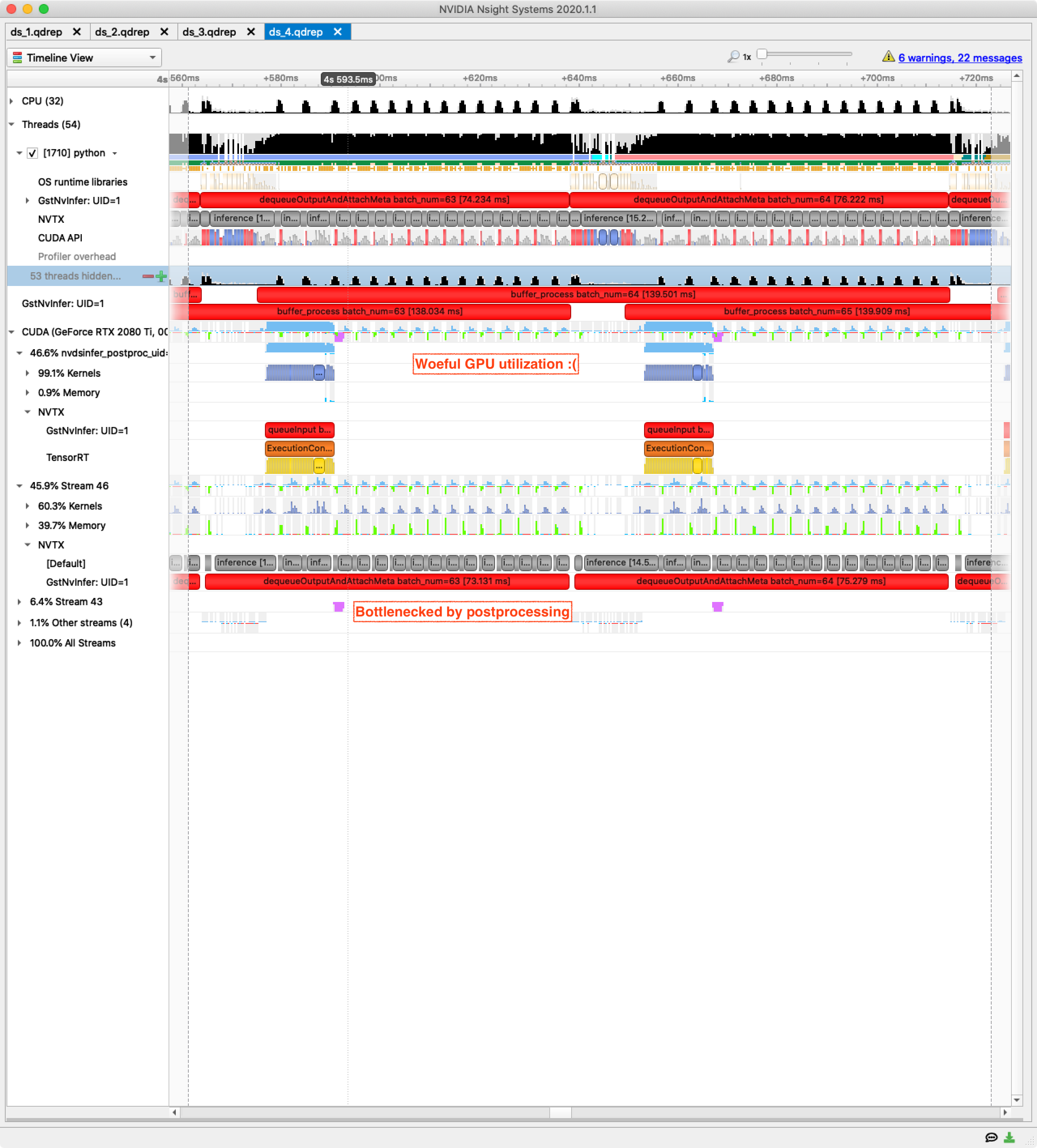
The problems are pretty clear, as annotated in the trace.
DeepStream is Awesome
But Hacked DeepStream is even better. :D
Stage 5: Horizontal Scalability #
| Code | Nsight Systems Trace | Gstreamer Pipeline |
|---|---|---|
| ds_trt_3.py, ds_tsc_3.py, ds_ssd300_3.py | ds_3_2gpu_batch16_device.qdrep | ds_3_2gpu_batch16_device.pipeline.dot.png |
{kind=link}
Doubling the hardware available to our Python-based pipeline boosted throughput from 350 FPS to 650 FPS, around an 86% increase. This was a single Python process driving two very powerful GPUs so it’s a great result. Given the measured GIL contention at around 45% scaling further would have become less efficient, perhaps requiring a multi-process approach.
Our DeepStream pipelines have been launched from Python, but with no callbacks beyond an empty once-per-second message loop so there is no chance of GIL contention. Measured without tracing overhead these DeepStream pipelines show perfect 100% scalability (at least from 1 to 2 devices), topping out at 1840 FPS. It’s like Christmas morning.
Incidentally, whereas most of the previous stages suffer from a roughly 15% hit to throughput with Nsight Systems tracing enabled this pipeline takes a 40% drop. You’ll see this difference if you download and analyze the linked trace files.
Conclusion #
We have a pipeline capable of doing 1840 FPS of useful object detection throughput, and this is phenomenal. This should convincingly demonstrate the effectiveness of these technologies working together.
Despite the huge gains delivered by TensorRT optimization and the efficient scalability of DeepStream, TorchScript is the unsung hero of this story. The ability to easily export any Pytorch model without worrying about missing layers or operations is huge. Without TorchScript and libtorch I would still be writing TensorRT plugins.
In future articles I’ll delve deeper into the TorchScript export process and explain some of the portability and performance pitfalls.
Caveats, Limitations and Excuses #
The Gstreamer/DeepStream pipelines used above do not reflect 100% realistic usage. If you review the pipeline diagrams (e.g. ds_3_2gpu_batch16_device.pipeline.dot.png) you’ll see a single file is being read and piped into the nvstreammux component many times. This is how you would handle multiple concurrent media streams into a single inference engine, but the real reason I’ve done this is to work around a limitation of nvstreammux to do with batching. Read the linked issue for the details, but it is fair to say that nvstreammux is not intended for assembling efficiently-sized batches when processing a small number of input streams.
Also as noted above, my “Hacked DeepStream” code is not yet publically available. I’ll work to tidy this up and if I’m sure of the licensing situation I’ll make this available.
Finally the code in the associated repository is not polished tutorial code, it is hacky research code so caveat emptor.